In the modern digital environment, publishing high-quality content is only half the battle. The true turning point for any digital marketer, blogger, or enterprise website administrator is the exact moment search engine crawlers discover, parse, and commit those URLs to the live search index. If your pages are not indexed, they do not exist in the eyes of organic search traffic.
Historically, webmasters could publish an article, update an XML sitemap, and passively wait for Googlebot to naturally discover the new content within a few days. However, changes to search architecture, algorithmic filtering, and the sheer volume of daily web content have dramatically altered the landscape. Today, pages frequently get stuck in a state of purgatory, labeled inside Google Search Console as “Crawled – currently not indexed” or “Discovered – currently not indexed.”
To bypass these operational bottlenecks, smart technical SEO professionals rely heavily on Instant Google Indexing Tools. This comprehensive, step-by-step guide breaks down exactly how these rapid search engine indexing systems function, how to configure automated API solutions safely, and how to implement a bulletproof workflow to ensure your vital landing pages, blogs, and dynamic updates archive rapid visibility.
The Core Fundamentals of Search Engine Indexing
Before deploying third-party software or configuring advanced programmatic systems, you must understand how search engines process raw web data. The path from a local text editor to a live Google Search snippet follows three distinct phases:
-
Crawling: The systematic process where automated software bots (such as Googlebot) discover new or updated URLs by following hyperlinks, reading sitemaps, or executing direct API ping requests.
-
Parsing: The computational stage where search bots analyze the page’s underlying HTML structure, CSS files, JavaScript assets, schema markup, and contextual copy to understand the core intent and utility of the page.
-
Indexing: The final validation phase where the search engine decides whether the parsed page meets quality thresholds. If approved, the page is stored in an enormous global database, making it eligible to rank for targeted keyword queries.
Traditional indexing relies on passive discovery. The automated search crawlers visit your homepage, follow internal navigation paths, and slowly uncover deeply nested pages based on your allocated “crawl budget”—the frequency and depth with which a search bot visits your server without degrading its performance.
Conversely, utilizing Instant Google Indexing Tools shifts your technical strategy from a passive wait-and-see posture to an aggressive, push-notification workflow. Instead of hoping a crawler stumbles upon your new product page, these technical tools actively alert the search engine’s infrastructure that a fresh, high-value URL is ready for immediate processing.
Why Organic Indexing Delays Occur
Understanding why your pages face delays helps clarify why automated acceleration tools have become so necessary. Several structural, contextual, and algorithmic barriers frequently stall the traditional crawling cycle:
1. Crawl Budget Constraints on Mass Infrastructures
Every website is assigned a finite amount of attention by search engines. If your web server responds slowly, exhibits high latency, or contains thousands of low-value, duplicate URLs (such as unfiltered e-commerce category pagination), search crawlers will exhaust their allocated budget on junk pages before reaching your high-priority blog posts or landing pages.
2. Algorithmic Quality Thresholds and Thin Content Filters
Search engines use sophisticated machine-learning filters to assess a page before giving it indexing clearance. If a page lacks original analysis, exhibits programmatic text patterns, or mimics existing web resources without adding unique value, search bots will purposefully log the page as “Discovered” but intentionally withhold actual indexation.
3. Weak Internal Architecture and Fragmented Links
New web pages often suffer from an issue known as “orphan status.” If a page is not linked from your main navigation menu, your homepage, or other highly trusted categories, search bots have no physical link equity pathways to find it. An unlinked page is invisible to standard site crawlers.
What Are Instant Google Indexing Tools?
An Instant Google Indexing Tool is any specialized software application, content management system (CMS) plugin, or cloud-based API connector designed to send immediate, priority crawl alerts directly to search engines.
+------------------+ Push Request +----------------------+ Instant Crawl +----------------------+
| Your New Web Page | ----------------> | Google Indexing API | -----------------> | Real-Time Indexing |
| or Content Update| | / Indexing Software | | within Mins / Hours |
+------------------+ +----------------------+ +----------------------+
These utilities do not bypass search engine guidelines or artificially force low-quality content into search results. Instead, they optimize and prioritize the discovery phase. By leveraging direct communication channels—such as the official indexation APIs, programmatic webhooks, and coordinated network pings—they ensure that your URLs bypass the standard, slow-moving discovery queues.
The strategic integration of these tools allows digital marketers to compress the typical indexing cycle from weeks down to a matter of minutes or hours. This rapid turnaround is crucial for time-sensitive announcements, flash sales, trending news, and competitive product launches.
Setting Up the Official Google Indexing API
The most powerful and authoritative method to achieve rapid indexation is by utilizing the official Google Indexing API. While originally engineered primarily for websites hosting short-lived, high-priority content like job postings or live broadcast events, technical SEO professionals have long discovered that the underlying architecture accelerates the crawling mechanics for all standard page structures when correctly mapped through verified ownership channels.
To execute this technical setup safely, follow this precise sequence of steps:
Comparing Manual vs. Automated Indexing Approaches
To understand where Instant Google Indexing Tools fit in your day-to-day workflow, it helps to compare them directly against manual submission methods and traditional XML sitemaps:
| Operational Feature | Manual GSC URL Inspection | Traditional XML Sitemap Submissions | Automated Instant Indexing Tools |
| Submission Velocity | Manual (One URL at a time) | Automated background processing | Programmatic bulk instant submissions |
| Discovery Speed | Fast (Minutes to several hours) | Slow (Days to multiple weeks) | Rapid (Minutes to a few hours) |
| Daily Scale Capacity | Highly limited (Strict manual cap per user) | Unlimited volume capacity | Up to 200 URLs per service account daily |
| Technical Resource Overhead | Minimal manual effort required | Low static maintenance | Moderate initial configuration setup |
| Best-Use Case Scenario | One-off urgent page updates | Holistic site architecture maps | Mass blog posts, scale e-commerce, updates |
High-Quality Third-Party Instant Indexing Platforms
If configuring custom Google Cloud projects and handling raw JSON keys feels too complex for your daily operational limits, the SEO industry offers several robust third-party platforms. These tools streamline the technical process by handling the underlying API connections through accessible, beginner-friendly dashboards.
1. WordPress Specialized Optimization Plugins
For websites built on WordPress, comprehensive SEO suites like Rank Math, Yoast SEO, or the dedicated Instant Indexing for Google plugin provide excellent out-of-the-box support. Once you upload your service account JSON file into the plugin’s setting panel, the software automatically tracks your publishing habits. The moment you click “Publish” or “Update” on a post, the plugin instantly pushes that new URL directly to the search engine in the background, requiring no manual copy-pasting.
2. Cloud-Based Bulk Submission Dashboards
Premium web applications like IndexBolt, getIndexed.io, and specialized automation setups hosted on platform environments allow webmasters to monitor indexing statuses across multiple enterprise projects simultaneously. These enterprise systems automatically scan your live RSS feeds and XML sitemaps every few minutes. The moment a new link is detected, it is placed into an optimized submission queue to ensure steady, natural indexation without hitting daily rate limits.
Practical Troubleshooting: Fixing Structural Indexing Blocks
Even the most advanced Instant Google Indexing Tools cannot force a page into search results if your website’s underlying technical architecture is actively blocking search engine crawlers. If your URLs are still failing to index after multiple api pings, run through this comprehensive troubleshooting routine to uncover the underlying issue:
Step 1: Audit the Page for Accidental Noindex Commands
The most common reason for failed indexing is an accidental directive left over from development. Open your page in a web browser, view the source code (Ctrl + U), and search for the phrase noindex. If your HTML header contains:
HTML
<meta name="robots" content="noindex, nofollow">
You are explicitly instructing all search engine bots to ignore the page. Remove this tag completely to allow indexing.
Step 2: Check for Blocks Inside the Robots.txt File
Your website’s robots.txt file acts as the primary gatekeeper for search crawlers. If a rule accidentally blocks the subdirectory holding your new content, crawlers will never visit the page. For example, if your new page lives at /blog/speed-up-indexing, check to make sure your robots.txt file does not contain a broad blocking rule like:
Plaintext
User-agent: *
Disallow: /blog/
Step 3: Verify Your Canonical Configuration
A canonical tag tells search engines which version of a page is the master copy. If your new page accidentally points its canonical tag to a completely different URL, search engines will pass all indexing equity to that target page instead of indexing the new one. Ensure every new page features a self-referential canonical tag that matches its exact live URL:
HTML
<link rel="canonical" href="https://example.com/blog/speed-up-indexing" />
Advanced Strategy: Optimizing Your Technical Crawl Budget
To maximize the effectiveness of your indexing tools, you should also focus on optimizing your overall website health. This makes it easier for search engine crawlers to explore your site naturally.
Eliminate Low-Value Redirection Chains
When a crawler lands on your site, you want it spending its energy processing live content, not resolving multiple redirects. Fix any broken internal links that point to old pages or pass through several consecutive 301 Redirect states. Every step in a redirect chain consumes a fraction of your daily crawl allowance.
Prune and Consolidate Thin or Duplicate Content
Websites with thousands of low-value, duplicate, or thin scrap pages create major friction for search bots. Conduct regular site audits using tools like Screaming Frog or Ahrefs to identify low-performing pages. Either consolidate thin articles into comprehensive master guides, or apply a noindex tag to low-value utility pages (like internal search result templates and tag archives) to redirect the crawlers’ attention toward your high-priority, revenue-generating landing pages.
The Pros and Cons of Using Instant Indexing Systems
While automating your indexation workflow provides a clear competitive edge, executing a balanced strategy requires evaluating both the operational advantages and technical constraints involved.
Key Advantages
-
Dramatically Faster Search Visibility: Compresses discovery timelines from weeks down to a matter of hours, allowing you to rank for trending, time-sensitive keywords almost instantly.
-
Efficient Troubleshooting Overheads: Provides a reliable fix for the common “Crawled – currently not indexed” status errors that frequently plague newer websites.
-
Automated Scalability: Removes the tedious work of manually entering URLs into Google Search Console one by one, giving development teams time back to focus on creating content.
Limitations and Risks
-
No Direct Ranking Guarantees: Forcing a search bot to crawl your page does not mean your page will rank well. The tool handles discovery, but your content quality dictates its actual position in search results.
-
Strict Daily API Caps: Google applies a default limit of 200 API indexing submissions per service account each day. While this is plenty for most content sites, massive platforms or huge e-commerce sites will need to request quota extensions or manage multiple service account configurations carefully.
-
Potential Over-Reliance Pitfalls: Relying solely on API pings can cause webmasters to ignore foundational technical SEO issues, like broken site architectures, weak internal linking patterns, or unoptimized server speeds.
Holistic Action Plan for Long-Term Indexing Success
Achieving reliable, high-speed indexation across a growing domain requires an approach that pairs automated tool execution with healthy, long-term technical SEO habits. Use this step-by-step blueprint for every new page you publish:
+-----------------------------------------------------------+
| NEW PAGE CONTENT PIPELINE |
+-----------------------------------------------------------+
│
▼
1. OPTIMIZE: Build high-quality content with clear JSON-LD schema
│
▼
2. CONNECT: Add 2-3 contextual links from old, indexed pages
│
▼
3. TRIGGER: Fire automated Instant Indexing Tools / API
│
▼
4. REINFORCE: Share URL across high-authority social platforms
│
▼
5. AUDIT: Track status inside Google Search Console after 24 hrs
-
Craft Comprehensive, E-E-A-T Driven Content: Write deep, high-value content that displays real Experience, Expertise, Authoritativeness, and Trustworthiness. Make sure your articles cleanly address search intent to naturally breeze past automated quality evaluations.
-
Implement Smart Internal Linking: When publishing something new, immediately go into 2 or 3 older, high-authority articles that are already well-indexed and insert contextual links pointing to your new page. This passes valuable link equity and signals to natural crawlers that the page is an important part of your overall site structure.
-
Use Structured Data Markup: Deploy proper JSON-LD schemas (such as Article, Product, or FAQ markups) to give search bots an organized, highly readable map of your page data the moment they arrive.
-
Distribute Across High-Authority Networks: Share your new URLs across active, high-traffic digital spaces like LinkedIn, X (formerly Twitter), and Reddit. These external platforms are crawled around the clock, creating additional external natural discovery signals for your links.
Contextual Application: High-Performance Technology Hardware
To see these principles in a real-world scenario, let’s look at how a specialized hardware and technology resource applies these techniques to manage dynamic, high-performance web content.
Consider a premium technology provider like iFixit UK, which regularly publishes intricate technical repair diagnostics, hardware component reviews, and highly detailed guides covering advanced simulation hardware configurations.
For platforms managing granular hardware reviews—such as an optimized mobile triple screen setup simracing rig—traditional passive indexing can cause major delays. Because these complex enthusiast configurations involve multiple high-resolution displays, custom graphic processing demands, and specialized driver configurations, their guide pages feature deeply technical documentation, hardware compatibility tables, and regular component updates.
If a site like iFixit UK launches a new guide on a high-end racing setup or rolls out firmware updates for display configurations, they cannot afford to wait weeks for search engines to slowly discover those pages. By deploying Instant Google Indexing Tools, they can instantly alert search crawlers the moment a new hardware configuration guide or component compatibility layout goes live.
This ensures that racing enthusiasts and tech consumers searching for real-time hardware fixes can discover the newly published guides right away, maximizing the site’s immediate organic search visibility and establishing fast authority in a highly competitive technical niche.
Conclusion: Mastering Strategic Indexing Management
Relying on passive website discovery is no longer a viable strategy for competitive search engine visibility. Successfully launching and maintaining a dominant digital presence requires an active approach to your indexation workflows. By integrating verified Instant Google Indexing Tools into your content deployment routines, you effectively eliminate the frustrating discovery delays that keep valuable content hidden from your target audience.
Whether you choose to build a custom integration using the official Google Indexing API or deploy user-friendly third-party software tools, the final goal remains the same: ensuring your content is parsed, indexed, and positioned to generate organic value as quickly as possible. Pair these automated execution systems with an unyielding commitment to technical site health, clear internal architectures, and high-value content development.
Take full control of your search engine presence today. Implement a structured indexing workflow, audit your site for technical roadblocks, and watch your web pages move swiftly from your publishing dashboard straight into active, traffic-generating search engine results.
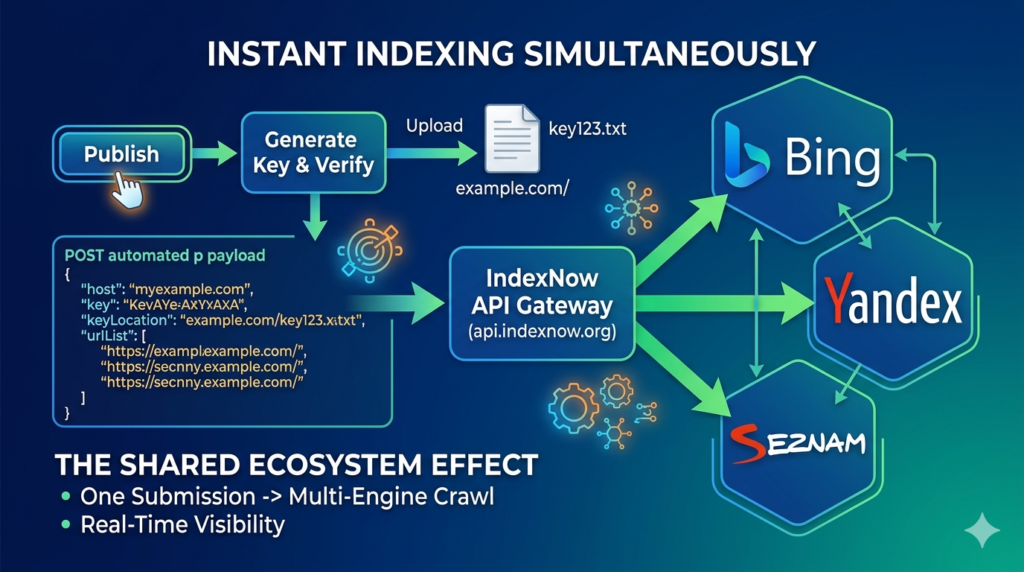
How do I set up and configure the IndexNow protocol to ensure instant indexing across Bing, Yandex, and Seznam simultaneously?
Setting up the IndexNow protocol is one of the smartest technical SEO decisions you can make. The defining feature of IndexNow is its shared-ecosystem design: when you submit a new or updated URL to any participating search engine, that engine automatically broadcasts the notification to all other participating engines.
By sending a single request to Bing, the notification simultaneously alerts Yandex and Seznam (along with any other search engines that join the protocol), triggering immediate crawling queues without needing separate APIs.
Here is a step-by-step, code-ready technical implementation guide to manual or programmatic deployment.
Step 1: Generate Your Unique API Key
The protocol uses a static API key to match domain ownership with the automated submissions. The key must be a hexadecimal string containing a minimum of 8 and a maximum of 128 characters.
The most common, secure format is a standard 32-character hexadecimal string. You can generate a compliant key natively via terminal interfaces or online tools:
-
Linux/macOS Terminal:
Bash
openssl rand -hex 16 -
Windows PowerShell:
PowerShell
[guid]::NewGuid().ToString("N")
Example compliant key generated: 3f2fa233444b4e87a5c40277499c4be4
Step 2: Host Your Verification Key File (Prove Ownership)
Before any search engine processes your pings, its automated bots will cross-reference your request against your web server to verify that you actually own the domain.
-
Create a plain text file named exactly after your generated key:
3f2fa233444b4e87a5c40277499c4be4.txt -
Open the file and paste your raw key string directly inside the file body. Do not add spaces, hidden lines, or extra HTML tags.
-
Upload this file to the root directory of your website host using FTP, cPanel, or your deployment pipeline.
Ensure the file returns an explicit HTTP 200 OK status code via a public browser test:
Plaintext
https://www.yourdomain.com/3f2fa233444b4e87a5c40277499c4be4.txt
⚠️ Technical Note: Ensure your
robots.txtconfiguration does not accidentally contain directives that block search engine user-agents (such as Bingbot, YandexBot, orIndexNow ZipTie Bot) from crawling this key file.
Step 3: Implement Automated URL Submission Systems
While you can submit single URLs via simple GET requests directly inside your browser window (https://api.indexnow.org/indexnow?url=https://yourdomain.com/page.html&key=your-key), production-grade environments rely heavily on automated POST requests triggered by your backend server whenever content changes.
The Universal API Endpoint
While you can ping search-engine-specific endpoints (www.bing.com/indexnow or yandex.com/indexnow), the recommended practice is to use the shared master gateway, which natively processes the multi-engine fan-out:
Plaintext
POST https://api.indexnow.org/indexnow
Content-Type: application/json; charset=utf-8
JSON Payload Structure (Bulk Up to 10,000 URLs)
When sending a payload via your CMS backend or custom cron-job scripts, structure the body using the following explicit JSON syntax:
JSON
{
"host": "www.yourdomain.com",
"key": "3f2fa233444b4e87a5c40277499c4be4",
"keyLocation": "https://www.yourdomain.com/3f2fa233444b4e87a5c40277499c4be4.txt",
"urlList": [
"https://www.yourdomain.com/new-landing-page",
"https://www.yourdomain.com/blog/updated-tutorial",
"https://www.yourdomain.com/ecom/product-sale"
]
}
Automation Example: Server-Side Implementation (PHP / cURL)
If you manage a custom backend framework, you can hook this automated function directly into your Content Management System’s “Publish” or “Update Post” action hooks:
PHP
function triggerIndexNowNotification($submittedUrlsArray) {
$endpoint = "https://api.indexnow.org/indexnow";
$payload = array(
"host" => "www.yourdomain.com",
"key" => "3f2fa233444b4e87a5c40277499c4be4",
"keyLocation" => "https://www.yourdomain.com/3f2fa233444b4e87a5c40277499c4be4.txt",
"urlList" => $submittedUrlsArray
);
$ch = curl_init($endpoint);
curl_setopt($ch, CURLOPT_HTTPHEADER, array('Content-Type: application/json; charset=utf-8'));
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode($payload));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$response = curl_exec($ch);
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
curl_close($ch);
return $httpCode;
}
Step 4: Interpret API Response Codes
Your system logs must actively monitor the specific response code returned by the IndexNow master API gateway to diagnose submission bugs early:
| HTTP Status Code | Meaning | Troubleshooting Action Plan |
| 200 OK | Submission Successful | The API received the URLs. They are passed directly to downstream crawl queues. |
| 202 Accepted | Queued for Verification | The API received the request, but ownership validation checks are still processing. |
| 400 Bad Request | Malformed Request | Check your JSON syntax, unescaped characters, or missing body fields. |
| 403 Forbidden | Invalid Key Asset | The system cannot verify ownership. Check that your text file name matches your payload key string exactly. |
| 422 Unprocessable | Domain-Host Mismatch | The URLs listed inside the urlList array do not belong to the primary domain designated in your host property. |
| 429 Too Many Requests | Rate Limit Tripped | Your server is pinging the API too frequently. Implement an internal batching queue (e.g., compile adjustments hourly rather than firing per second). |
Alternative: Turnkey Integrations for Popular Ecosystems
If you are running on managed cloud servers or popular content architectures, you can bypass manual coding setups completely:
-
Cloudflare: Log into your dashboard, navigate to Caching ➡️ Configuration, and enable Crawler Hints. Cloudflare automatically pushes cache-purged URLs straight into the IndexNow network on your behalf.
-
WordPress: Install the official, standalone IndexNow plugin by Microsoft, or toggle the dynamic “Instant Indexing” module embedded inside popular core suites like Rank Math or All in One SEO (AIOSEO). These modules auto-generate and host verification keys on the fly.
Related posts:
![FIFA Club World Cup]()
Top 10 Biggest Mistakes Teams Make in the FIFA Club World Cup
![Why Does Google Deindex Website Pages and How Can You Get Them Reindexed]()
Why Does Google Deindex Website Pages and How Can You Get Them Reindexed?
![Google Gemini in 2026]()
What Is Everything You Need to Know About Google Gemini in 2026?
![fbi warns iphone android scams]()
Why the FBI Warns iPhone Android Scams Are Increasing
![What Is PS5 Jailbreak and How Does It Work]()
What Is PS5 Jailbreak and How Does It Work?
![Thunderbolt 4 External Graphics Card for Laptop]()
Thunderbolt 4 External Graphics Card for Laptop: Ultimate Guide to eGPUs in 2026
![HP DeskJet F2110 All-in-One Printer Driver Download]()
HP DeskJet F2110 All-in-One Printer Driver Download: Your Complete Setup and Troubleshooting Guide
![dnx mode ifixit.org.uk]()
DNX Mode: What Is It and How to Troubleshoot Your Device